Edit (2008-11-09): Robert Bradshaw posted a patch to my code and the Cython implementation is now a lot faster. Click here to read more.
In a comment on a recent post, Robert Samal asked how Cython compares to C++. The graph below shows a comparison of a greedy critical set solver written in Cython and C++ (both use a brute force, naive, non-randomised implementation of a depth first search):
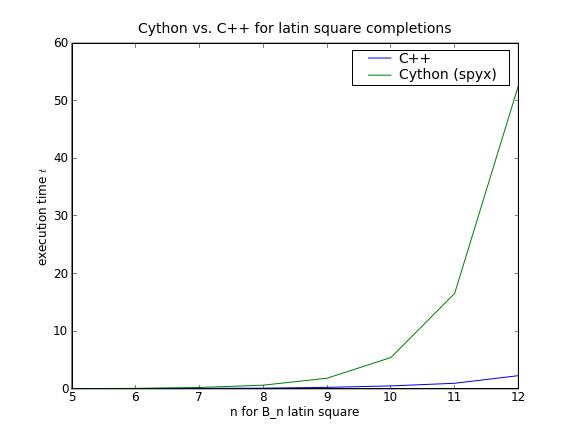
So things look good until n = 10. In defence of Cython, I must point out that my implementation was a first attempt and I am by no means an expert on writing good Cython code. Also, the Cython code is probably fast enough – in my experience, solving problems (computationally) for latin squares of order 10 is futile, so the code is more convenient for testing out small ideas.
edit: the code is here
edit: Robert’s code is here http://sage.math.washington.edu/home/robertwb/cython/scratch/cython-latin/
Comment form pending Cloudflare verification...
Loading comments…